https://make-a-video3d.github.io/
Text-To-4D Dynamic Scene Generation
Text-To-4D Dynamic Scene Generation, 2023.
make-a-video3d.github.io
https://arxiv.org/abs/2301.11280
Text-To-4D Dynamic Scene Generation
We present MAV3D (Make-A-Video3D), a method for generating three-dimensional dynamic scenes from text descriptions. Our approach uses a 4D dynamic Neural Radiance Field (NeRF), which is optimized for scene appearance, density, and motion consistency by que
arxiv.org
논문

발표된 지 얼마 안 된 정보라서 공개된 코드도 없고 체험해 볼 수도 없습니다. 다만 한참 예전에 Meta가 Make a video라는 이름으로 Text to video AI 생성 관련 기술을 발표했었습니다. Text를 입력하면 비디오를 생성해 주는 기술이었는데 gif 짤방 뽑아내기 좋아 보이던 기술이었습니다. 지금 이 것은 해당 기술의 발전형이라고 보시면 됩니다.
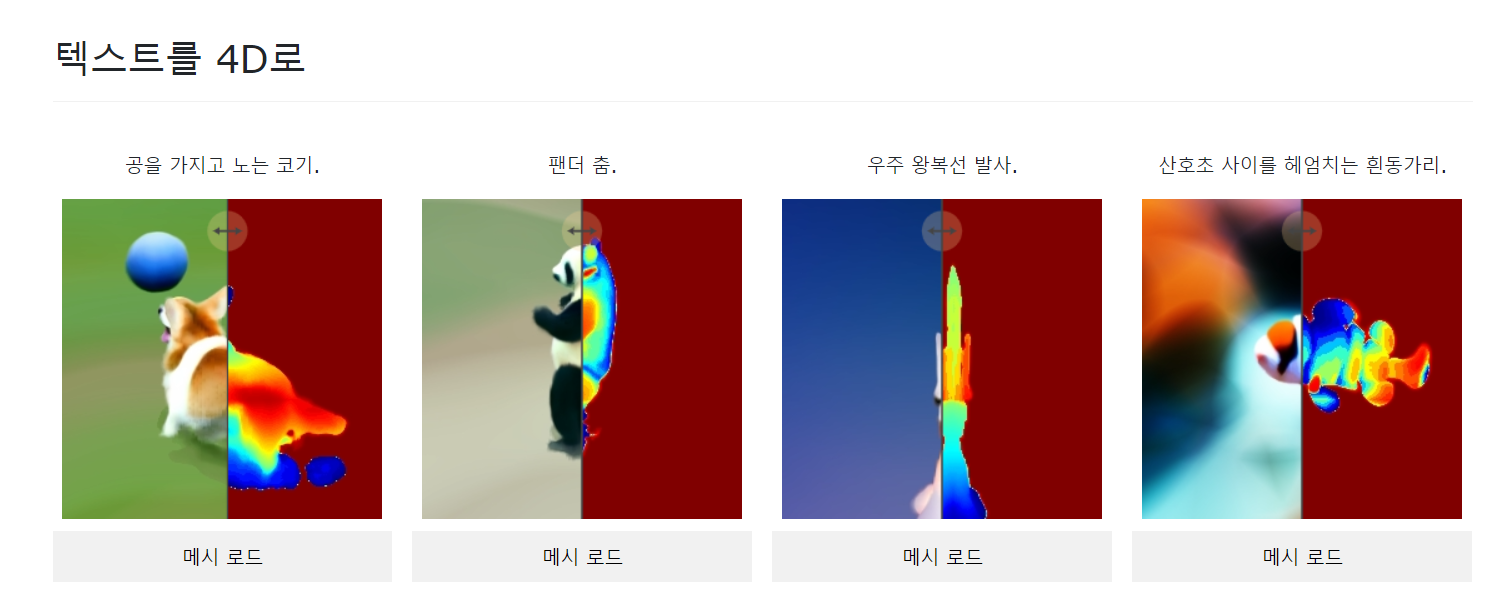
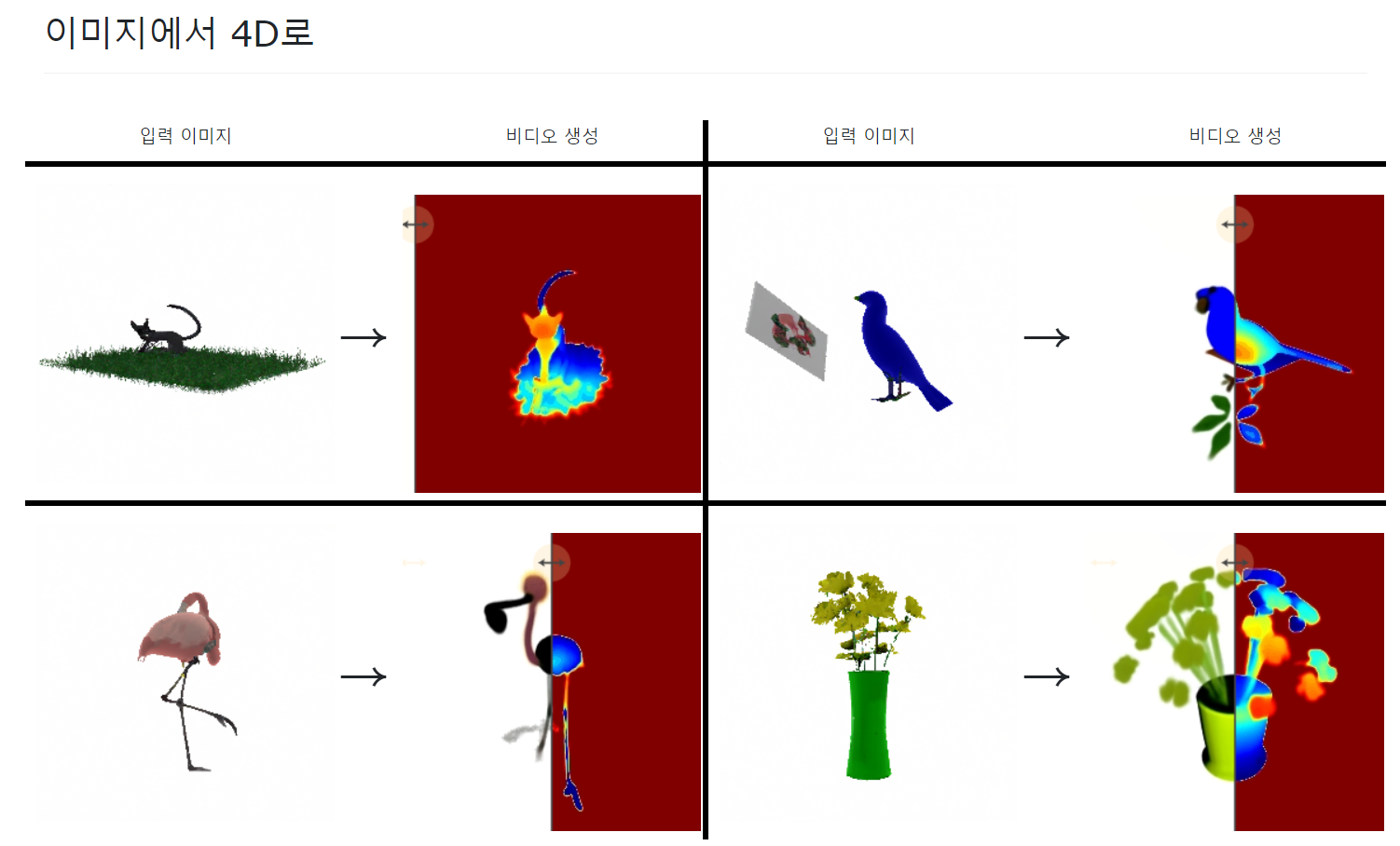
해당 툴은 Text로 애니메이션 3D를 생성하거나 / Image로 애니메이션 3D를 생성할 수 있습니다.
생성되는 메쉬의 정밀도나 형태는 Google이나 OpenAI가 만든 AI 3D 생성툴과 크게 다를게 없긴 하지만, Meta는 한술 더 떠서 텍스트를 인식하여 3D 애니메이션을 생성합니다. 물론 사람이 편집하기 쉬운 본 애니메이션은 아닌 것 같고 사람이 손보기 난해한 버텍스 애니메이션으로 보입니다. 그래도 이 정도면 꽤나 발전한 것 같습니다.
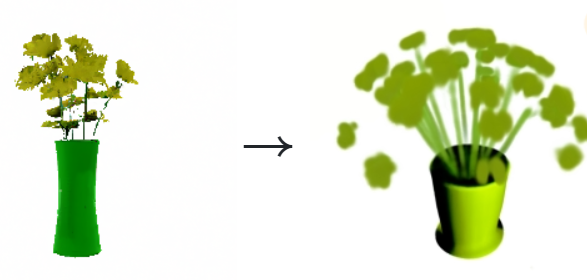
특이한 점은 텍스트 기반으로 생성하면 표현력이 꽤나 좋지만, 이미지를 기반으로 생성하면 표현력이 매우 떨어지는 것을 볼 수 있습니다. 위 이미지를 보시면 알겠지만 꽃의 줄기가 대부분 사라졌고 꽃의 모양도 제대로 드러나지 않습니다. 아무래도 AI가 맘대로 만들게 냅둬야 잘 나오는 게 아닐까 생각되네요.
아직까지 메쉬 흐름 같은걸 알 수 없지만 아마도 하이 폴리곤 기반일 것이라 예상되고 별도의 최적화가 필요할 것 같습니다. 2D AI는 완성도가 매일 오르고 있지만 3D AI는 거의 제자리걸음입니다. 2019년쯤에 공개된 Nvidia의 3D AI가 현재 4년이나 지났지만 여전히 퀄리티는 형편없습니다. 메쉬 최적화까지 자동으로 돼서 나오는 3D AI는 한 3~4년은 기다려야 나오지 않을까 싶습니다.
'IT 및 모바일 기기 > IT 소식' 카테고리의 다른 글
| New Bing - ChatGPT가 탑재된 Bing 사용 후기 (0) | 2023.02.26 |
|---|---|
| ChatGPT 회원가입 및 기본적인 사용 방법 (0) | 2023.02.10 |
| 아카라(Aqara) 홈 카메라 CCTV G2H PRO 구매 후기 (0) | 2023.01.25 |
| OpenAI가 개발하는 AI Text to 3D / Point-E 관련 정보 공개 (1) | 2022.12.24 |
| Novel AI(노벨 AI) 응용 아티스트 태그 사용 방법 (0) | 2022.11.27 |




댓글